
Hi Everybody,
I was wondering what others thought about the multiplet calculations in the various 10x user guides.
I have received some very helpful feedback from 10x, but I think something about the numbers being exactly the same still doesn't seem quite right to me. For example, you can compare the following tables:
3` GEX V2 (single-barcode):
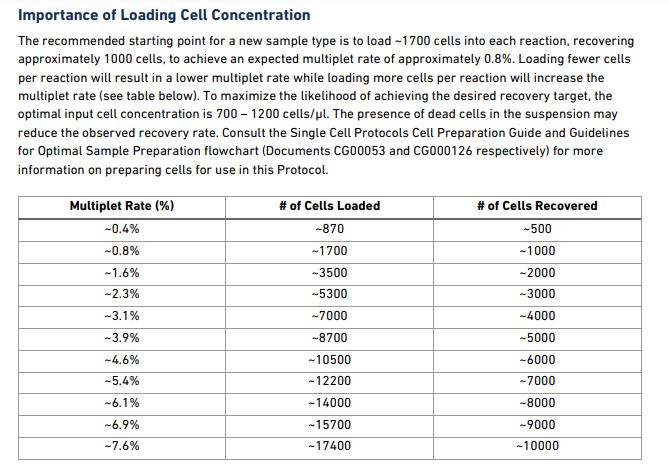
That table comes from page 18 in the V2 user manual.
3` GEX V3 (single-barcode):
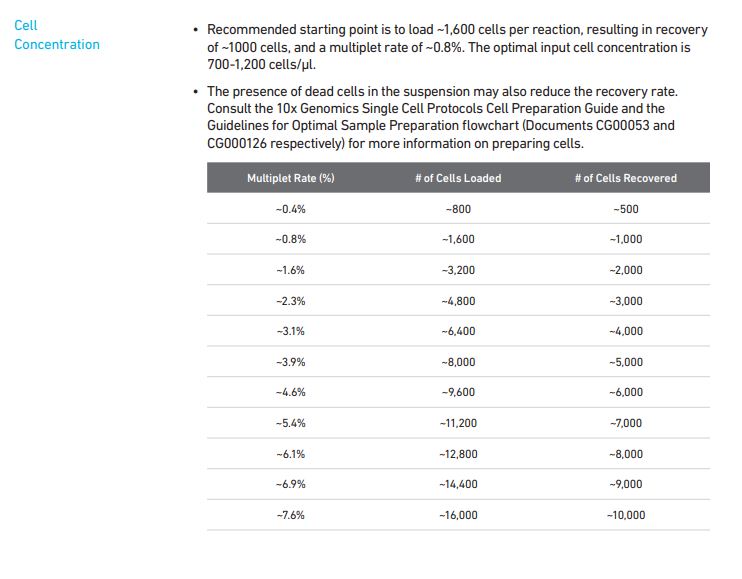
That table comes from page 17 in the V3 user manual.
3` GEX V3.1 (single-barcode):
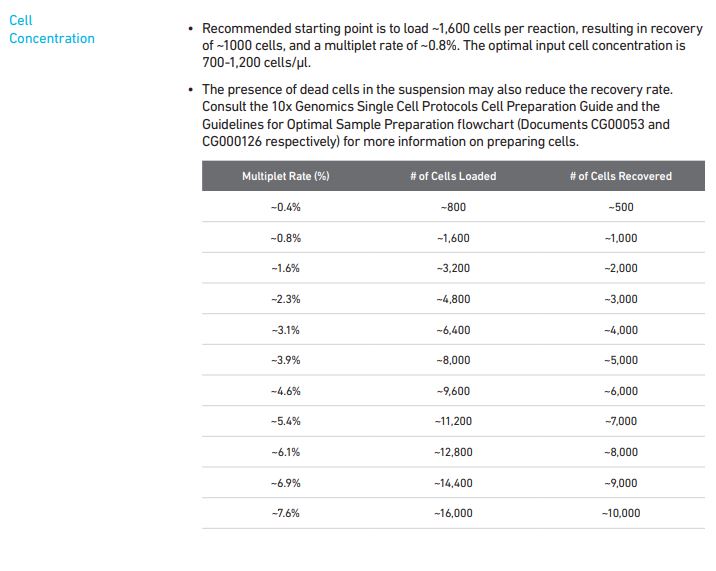
That table comes from page 18 in the V3.1 single-barcode user manual.
3` GEX V3.1 (dual-barcode):
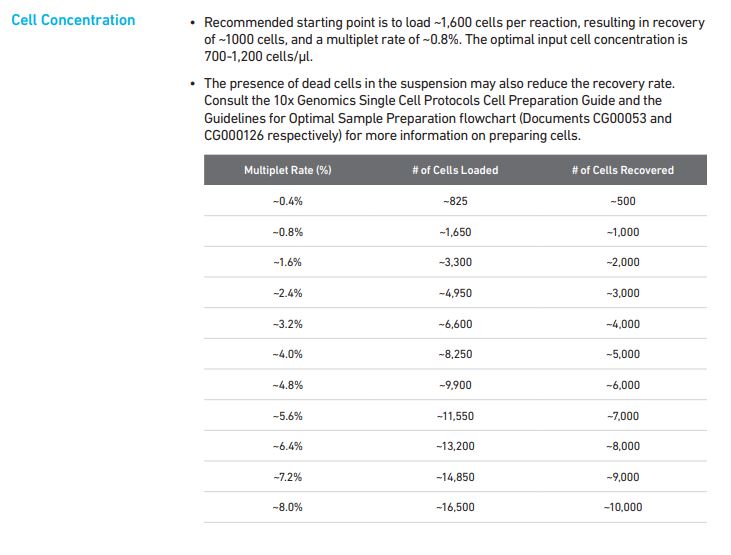
That table comes from page 18 in the V3.1 dual-barcode user manual.
I would usually expect dual-barcode libraries to have less index-hopping than single-barcode libraries (which can be a different cause of multiplets). However, I think this is meant to emphasize multiplets that specifically come from the Chromium Controller. So, in terms of the ballpark measurements, I think think that I agree with that (although I would not conclude that the multiplet rate was robustly slightly higher with the dual-barcode libraries).
My understanding is that those multiplet rates are supposed to be coming from an experiment with human and mouse cells like Figure 2 in Zheng et al. 2017:
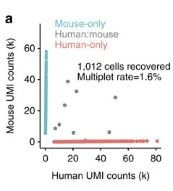
Likewise, I think Figure S1a emphasizes how the multiplet rates shouldn't be exactly the same (since you can see the difference from the trendline):
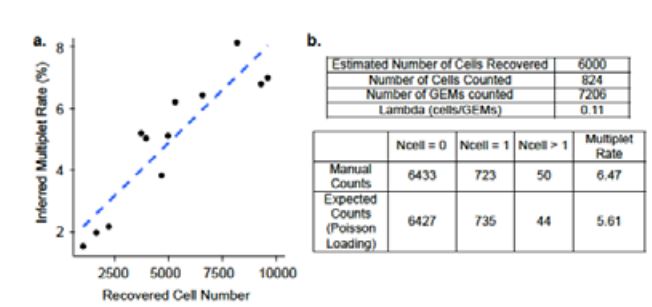
When I noted that the multiplet rates were the same but the loaded cells were slightly different between the user manuals (I assumed from slightly different estimates), I was provided the following explanation: "We load Beads: super-Poissonian and Cells: Poissionian to control for the multiple rate. That is why you see the [multiplet] rate uniform across chemistries though the # of cells recovered vary slightly."
I was also provided a link to the Zhang et al. 2019 review (I think for the term "super-Poissonian"), and the human-vs-mouse experiment described above was mentioned at a later part of the conversation.
What you all of you think?
Thank you very much,
Charles

I originally started taking notes on this because I thought the multiplet rate seemed high (especially with 10,000 recovered cells). I also thought I saw something similar a few years ago, with somewhere between 1% and 5% of cells from the wrong species (which I think is a fairly good match for those results). I also have some general barcoding discussions here and here, although I think this post is supposed to be primarily due to cell sorting over index hopping.
I guess if I had to pick some important message, I would say that this matches an importance in having replicates. If you can't do that from with multiple 10x samples, then hopefully some lower throughput technology can be used for selected markers of interest.
For example, I think Supplementary Figure S8c from the Zheng et al. 2017 paper is helpful for emphasizing that you shouldn't use 1 10x sample for estimating a cell type fractions for a given biological group:
The results also say things like "The size of the cluster suggests the multiplets comprises mostly B:dendritic and B:T:dendritic cells (Supplementary Methods). With ∼9k cells recovered per channel, we expect a ∼9% multiplet rate and that the majority of multiplets would only contain T cells. More sophisticated methods will be required to detect multiplets from identical or highly similar cell types."
In terms of the user manuals, it does also look to me like there was possibly 2 experiments instead of 4 experiments. However, if there was something about how the numbers were being calculated that caused the tables to look the way that they do, then that leaves open the question of how else the data could be represented.
Since I thought I saw more samples being processed with closer to 10,000 cells, I also kind of wondered if others thought this was surprising and thought it might be useful to open up for discussion. That may be the more important question.
For example, I wonder if others might agree that processing closer to 3,000 cells per sample could be OK (and maybe even better, if you processed more total 10x samples)?
Also, perhaps a better and shorter reply is that I am certainly happy to send another e-mail to 10x support (which has been very helpful in providing additional information).
However, if this discussion can help me come up with a different question to ask (compared to what I asked before), then I think that could be helpful.