Entering edit mode

6 months ago
WUSCHEL
▴
800
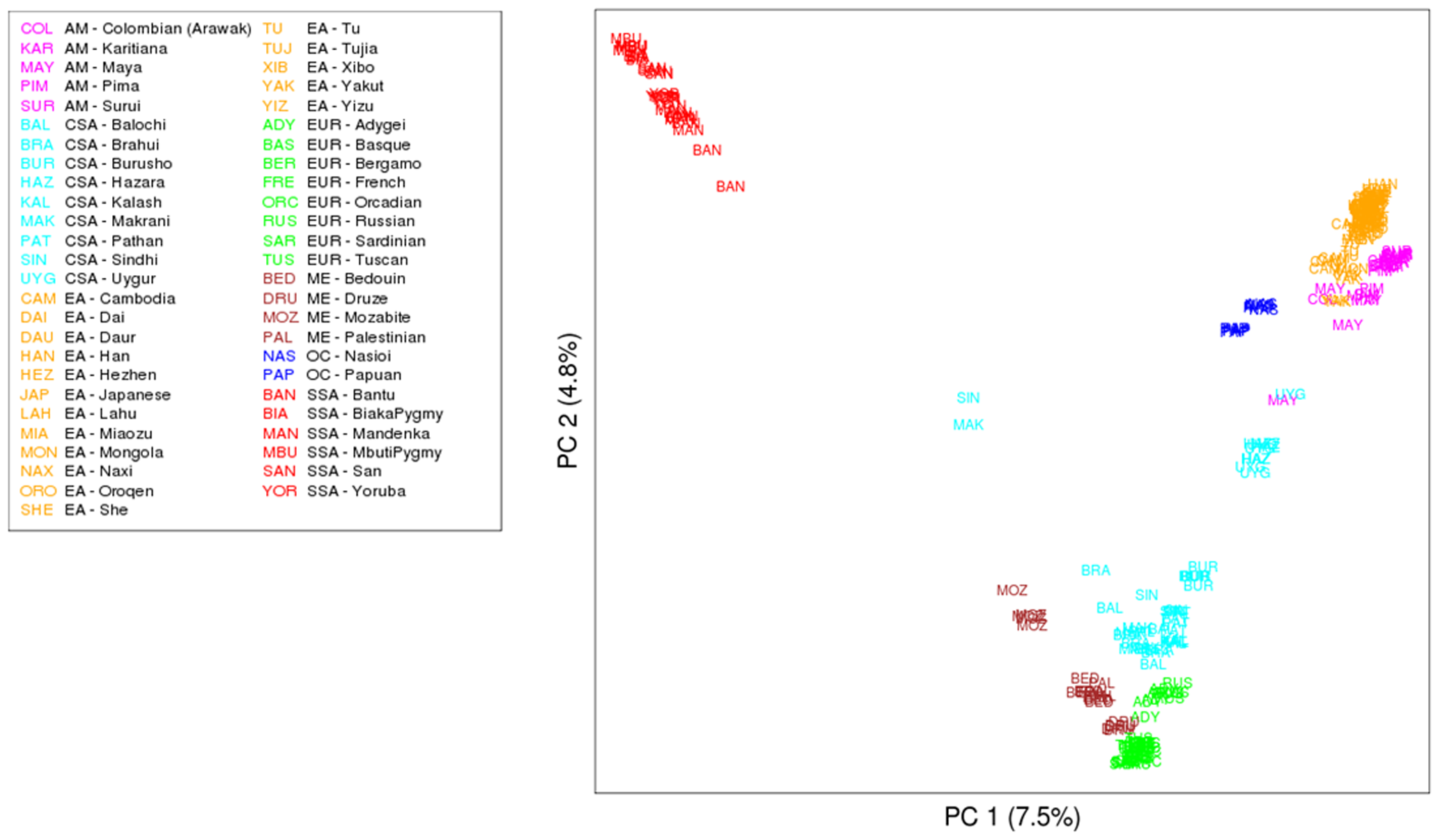
Very well clustered PCA analysis indeed provides insights into the underlying structure of biological data by identifying patterns and relationships among variables.
My question is, if we do not see OMICS (proteomics / metabolomics / transcriptomics) research, sample replicates data is not very well clustered in PCA plot, what does this mean? Does that means our samples/replicates looks similar?
How we can biologically interpret PCA results?
Aslo,if we see clear clustering in non neighegour PCA biplots, what are the downstream analysis we could perform? in otherwords, what is the point if looking at range of PC's in bi-plots?
Below two figures took from PCAtools: everything Principal Component Analysis by
Kevin Blighe & Aaron Lun


{kind=link}