Entering edit mode

6.9 years ago
afli
▴
190
Hi my friends, I do a fisher exact test by R, because I think the treatment would not affect the counts and I expect a uniform distribution of pvalue, but the histogram show U shape, with the 0 and 1 show large numbers. The code is as follows, could you please tell me why? Thank you very much!
test<-read.table("sample_fisher_test.txt")
test<-test[rowSums(test[,3:4])>5,]
for(i in 1:nrow(test))
{x<-c(test[i,1],test[i,3],test[i,2],test[i,4])
dim(x)<-c(2,2)
test$pvalue[i]<-fisher.test(x)$p.value}
ggplot(test, aes(x = pvalue)) +geom_histogram(binwidth = 0.05, fill = "lightblue", colour = "black")
dev.off()
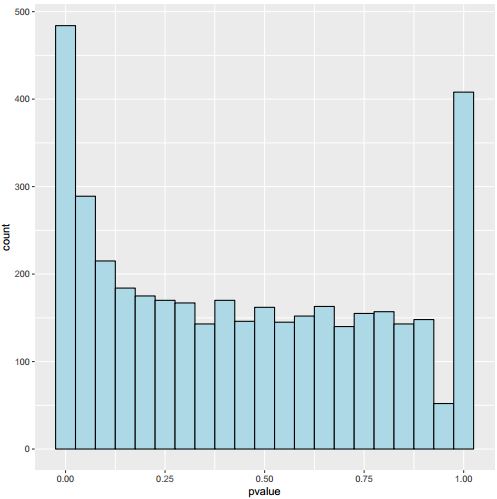
data is available at: https://de.cyverse.org/dl/d/D577D93C-F511-41EE-AC74-26E2B5203564/sample_fisher_test.txt

Why do you think it should be uniform?
I've just modified the content, I expect it to be, maybe it actually not. I just cannot understant the U shape.
Your comment does not add any information. I personally have too little of a statistical background to formulate expectations about p-value distributions. You should ask yourself if your statistical knowledge is sufficient to do so. As this is a pure statistics question, you might consider to post it on StackExchange. If you do, you can enhance your chance of a good response by following the guildelines on How To Ask Good Questions On Technical And Scientific Forums, because right now, your question lacks any details on what the experimental setup was.
Thank you ATpoint, I made the post in a hurry just now, sorry for that. I will read the guidelines carefully and do better next time. And I will post this on stackExchange to see if I can get some help.
Aifu.
Hi- See if this blog post helps you http://varianceexplained.org/statistics/interpreting-pvalue-histogram/ . To get better answers, it would be good to give some background about what you are testing as the U-shape may or may not be anything to worry about.
Thank you dariober, I've already seen this post, it is clear but the solution it provides could not solve my problem.