Entering edit mode

20 months ago
hafiz.talhamalik
▴
350
my sequences have names of more than 10 characters. but looks like phylip format takes only names with characters less than 10. How to deal with it ??? I tried shortening the names but cannot do that for all sequences



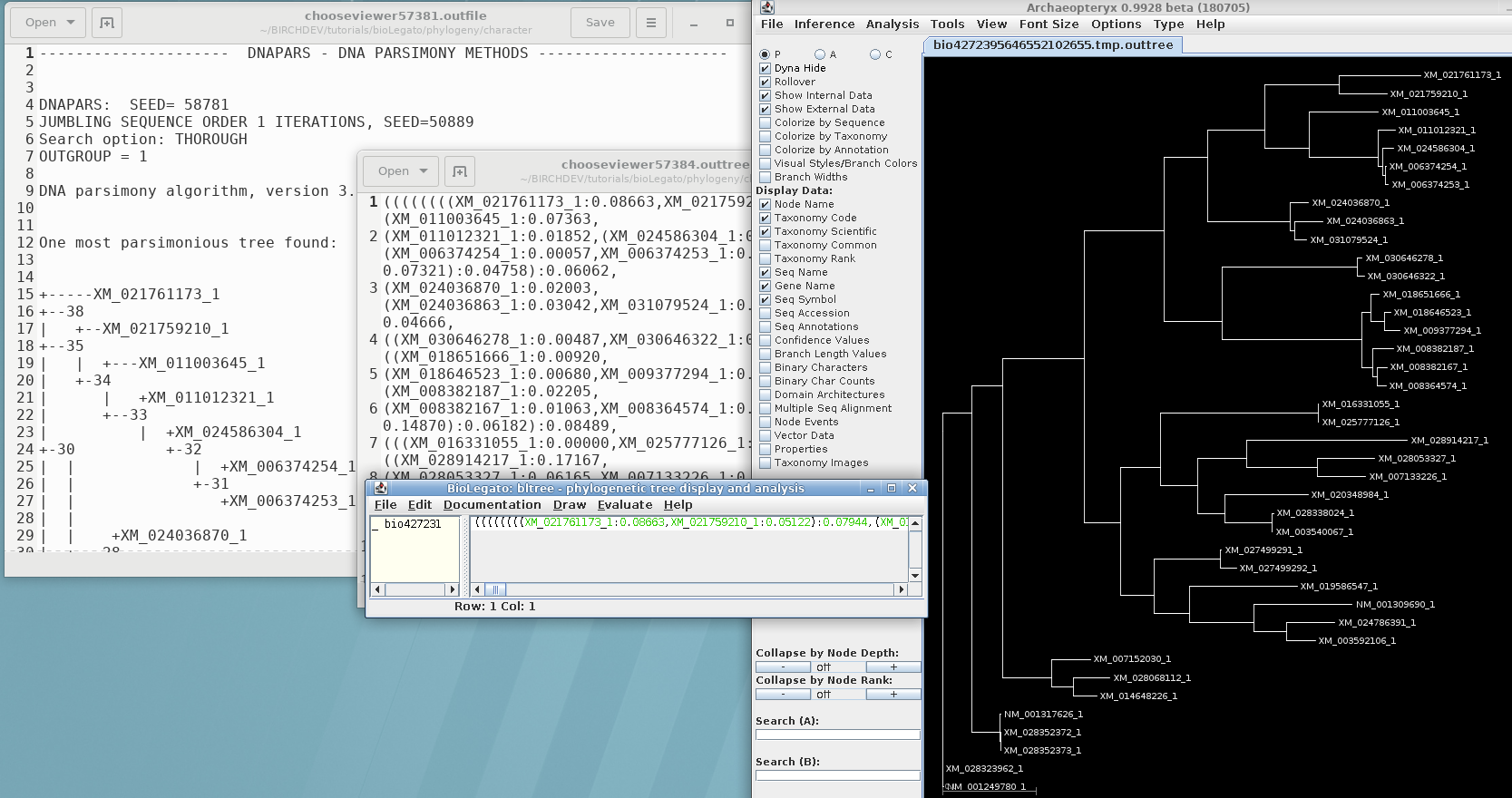
Thanks will look into it.